About
Httppp is a network capture analyzer which extract HTTP request response times
from a previously recorded network capture file.
It has been written because no free software which perform this analysis
existed. Even Wireshark does not provides those figures.
It is intended for measuring response time of HTTP inter-application calls
(so-called web-services), not to measure HTTP browsing user experience quality,
for which there are far better tools on the market (such as
Fiddler,
Firebug
and a bunch of expensive but far richer softwares hidden behind
buzzwords like "user experience management").
Actually, httppp does not perform any statistical analysis, but produces
a CSV file which can be easily imported into a spreadsheet software to be
analyzed through
pivot table feature
and to compute
percentiles of the
TTLB or TTFB distribution (see snapshots below)
Features
Httppp key features are to:
- Read network capture file in libpcap format, which is produced by most
network sniffers such as tcpdump
or Wireshark.
- Analyze TCP packets to find HTTP among them and match requests and replies
to compute response time (TTFB/time to first byte and TTLB/time to last byte)
along with usual information about an HTTP hit (host, path, return code,
source IP address, etc.).
- Provide a graphical user interface (GUI) to interactively browse hits and
TCP packets with interactive sort to easily find longest service calls
(or shortest, or 5xx return codes, etc.).
- Produce hits table in CSV format, to make it easy to import into a
spreadsheet software.
- The CSV format is designed to be easily transformed into a
pivot table
to group response times by host, path, source IP, return code, custom fields,
etc. depending on needs.
Disclaimer: I personnaly use a very well known non-free
spreadsheet software developed at Redmond, WA and am happy with it.
If you use another one, you're maybe a better free software advocate
than I am, but don't complain with its pivot table feature not being as
powerfull.
- The CSV format is also usable to draw a
distribution diagram by letting the spreadsheet software compute
percentiles.
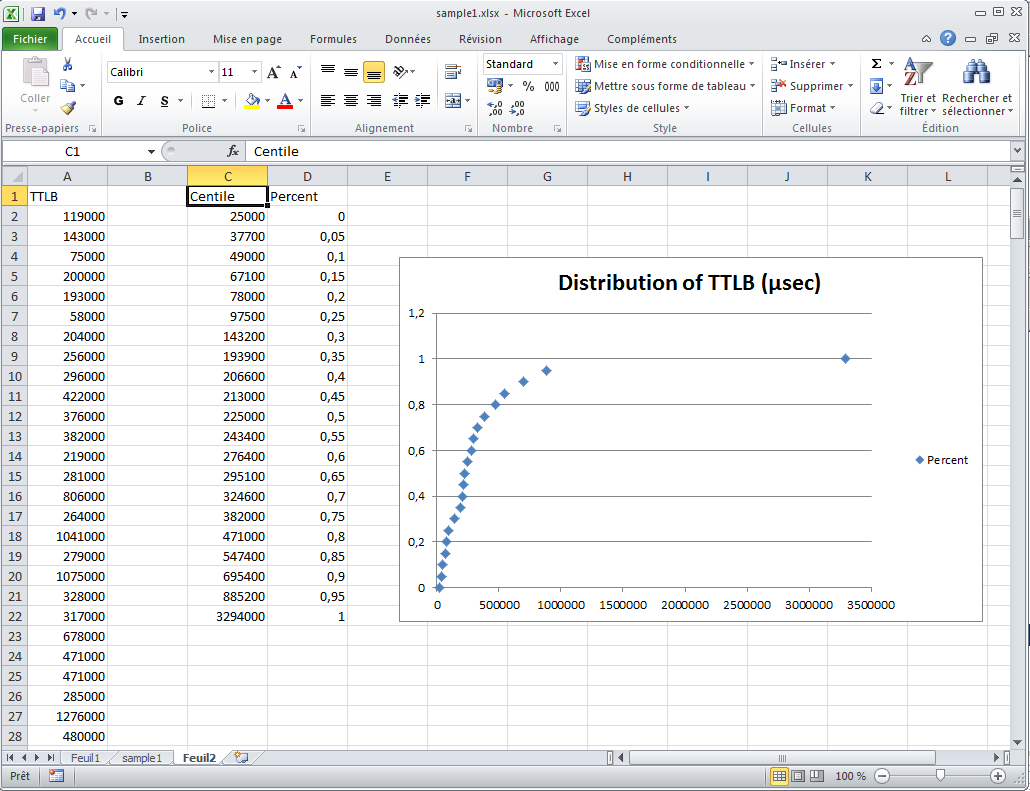
This is often the first diagram you'll wan't since it displays information
such as "80 % of requests are served in less than 600 ms".
- Support customizable fields to extract any information from the request or
reply. This is done with
regular
expressions
and make it possible to catch any header (such as Referer, Content-size or
SOAPAction) or any fragment of a POST payload (again, the SOAP action may be
relevant) or the reply payload. See snapshot below. Some interesting
regexp are:
- Referer:
Referer:\s*(\S+)
- SOAP action in header:
SOAPAction:\s*"(\S+)"
- SOAP action in POST:
<\w*:?Action[^>]*>([^<]+)</
- URI path without query string:
GET\s+(/[^?#]*)\S*\s+HTTP/1\.\d
- invoked method name in Spring HTTPInvoker serialized Java request:
([A-Za-z0-9._]*)..\[[^[]*$
- class name in Spring HTTPInvoker serialized Java request:
(com.mycompany.[A-Za-z0-9._]*[A-Za-z0-9_])
For exact syntax reference, please refer to
Qt's
QRegExp class documentation, since it's the regexp engine used by httppp.
Screenshots
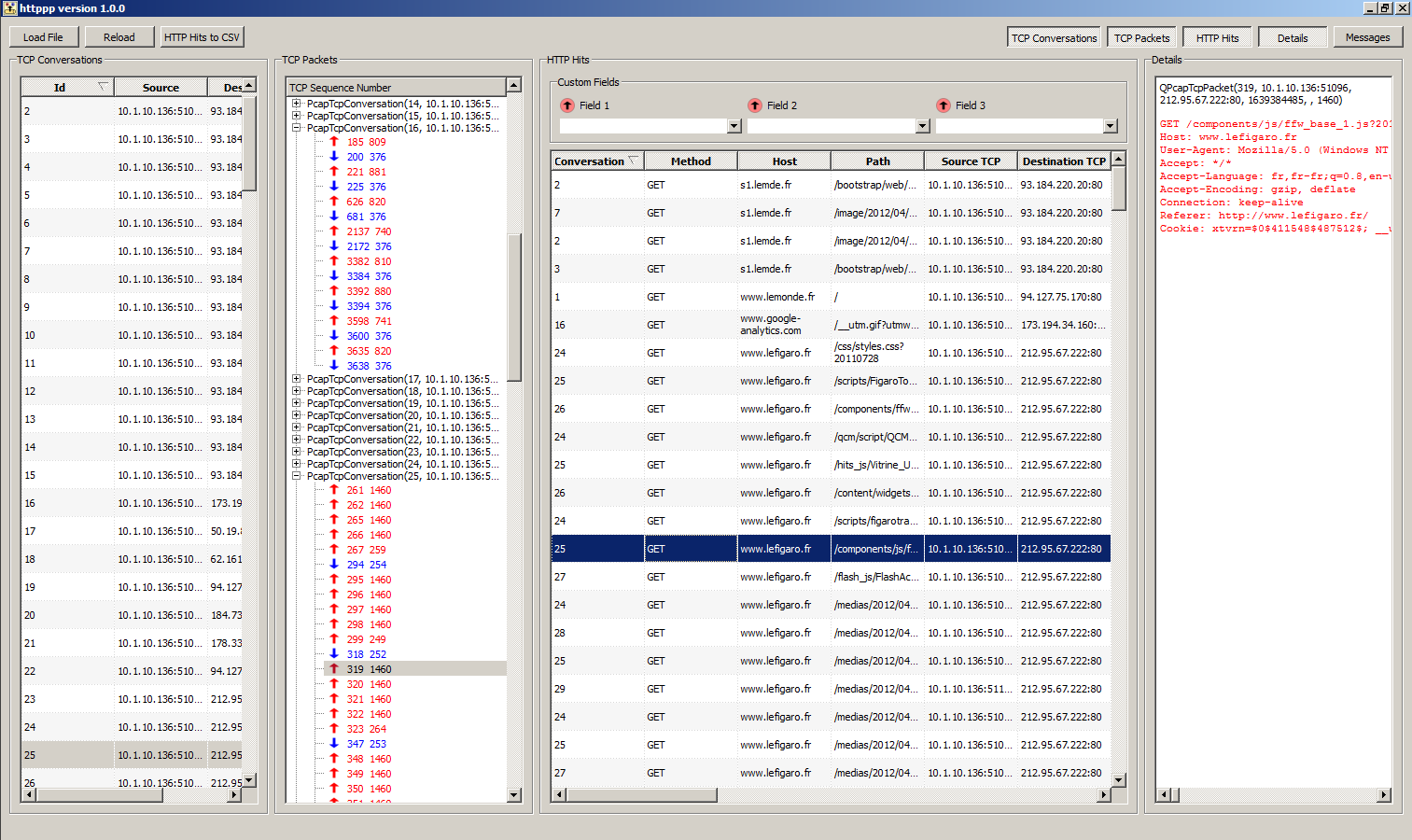
Main GUI displaying (from left to right): TCP conversations
list, TCP packets tree, analyzed HTTP hits table, packet content:
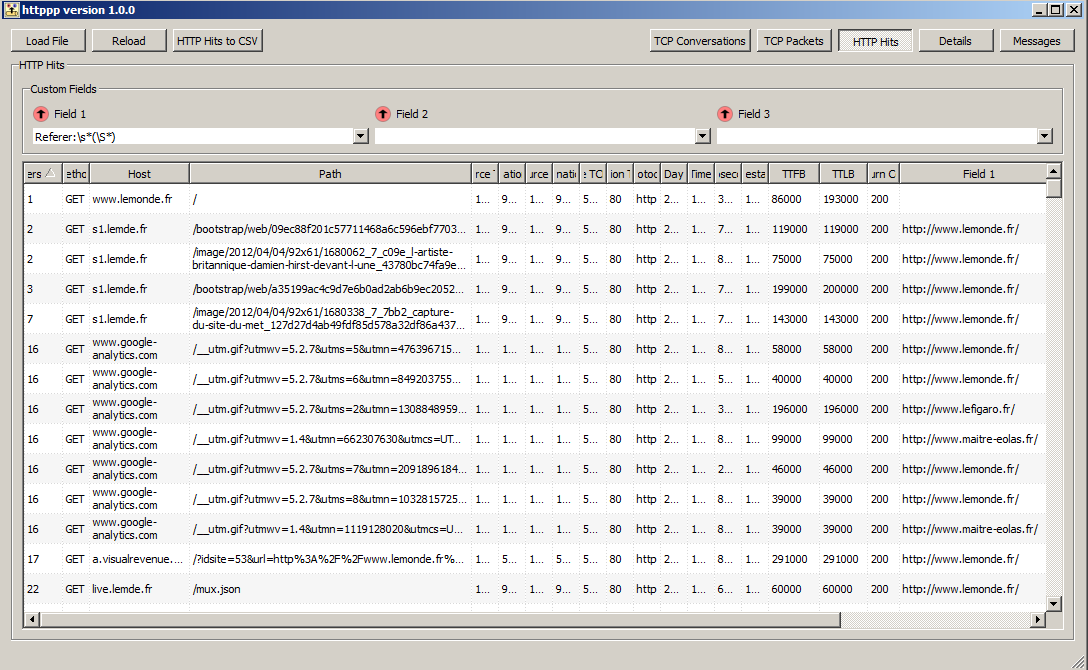
Main GUI with everything closed but HTTP hits table,
exhibiting regexp custom extraction of referer header in custom field 1:
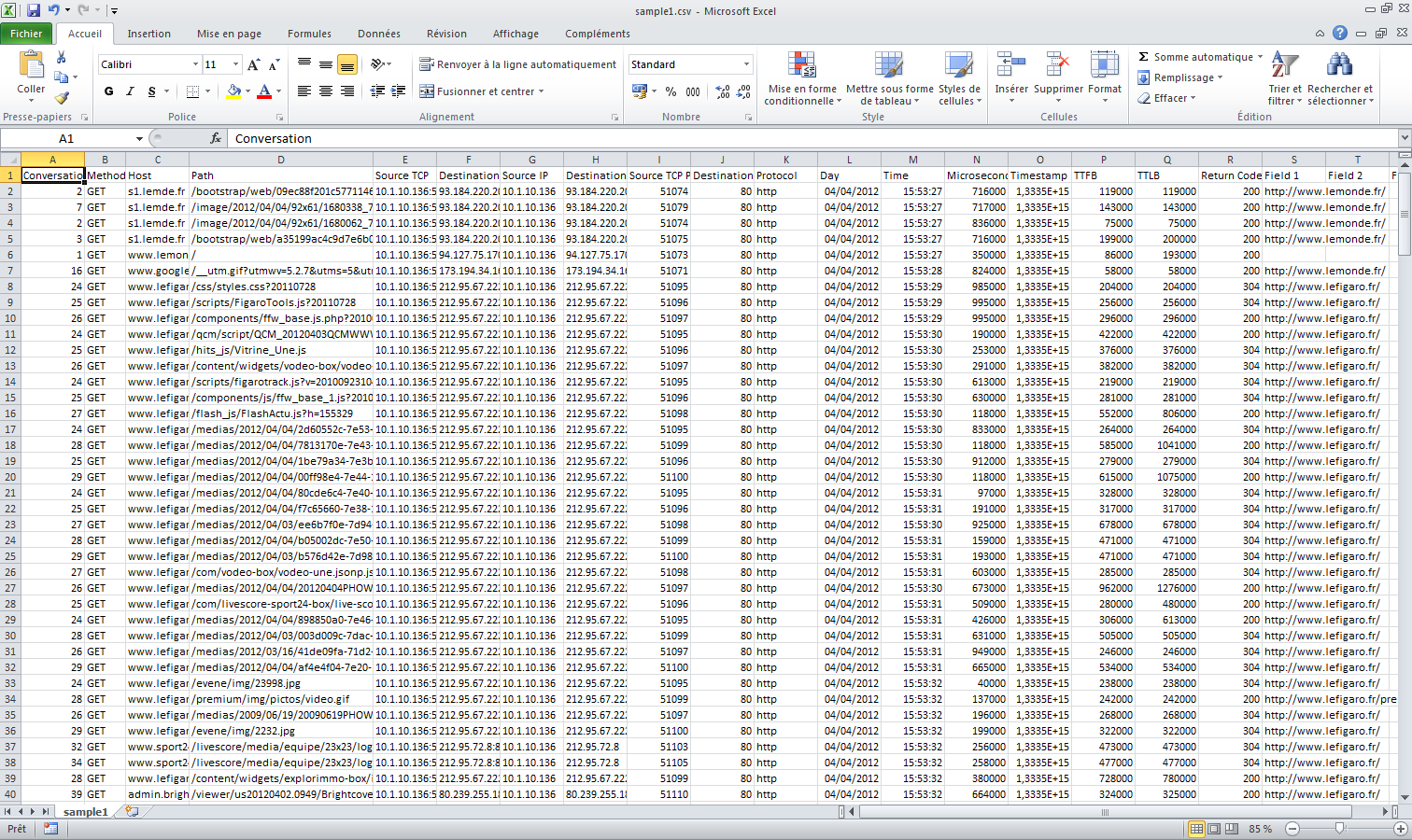
CSV HTTP hits file produced by httppp, displayed inside a famous
(whereas not free) spreadsheet software:
Same information analyzed in a pivot table (only 30 seconds of
manual work after previous snapshot):

Percentiles of TTLB distribution (yet another 30 seconds of
manual work later):
Known limitations and bugs
The most obvious limitation is due to the fact that, under heavy workload,
most network capture tools don't capture every packets but only
most of them.
Therefore most capture files will lack packets, which makes the analysis harder
(it's harder to reorder TCP packets when some packets are lacking) and produces
incorrect data (when the lost packet is the one containing the HTTP request,
even guessing that there was a request packet cannot tell at which
microseconds it occured). Even though httppp is resilient to packet lost in
many cases, they will create artifacts, such as:
- Some hits will be lost. If one of them is the longest or shortest, the
computing of maximum or minimum TTLB in your spreadsheet will be false.
- If a request packet is lost, its response will be considered as a part of
previous hit response if there is a previous hit in the same TCP connection,
hence the previous hit will be reported as longer than it is, possibly far
longer (especialy if the TCP connection has been inactive for a while).
Of course requests won't be mixed with previous ones if HTTP/1.1's keepalive
is not enabled, and it is easy to disable on the server side or on a reverse
proxy, if you use one.
HTTP features not (yet) supported:
- HTTPS/SSL traffic isn't analyzed.
- Proxied HTTP traffic isn't correctly analyzed (i.e. the host is assumed
to be set in request headers and the request URL is assumed to begin with a
slash).
- HTTP pipelining
would be misinterpreted and produce inconsistent figures. Please note that even
though it can be an optimization for web browsing in some circonstances,
HTTP pipelining is most of the time inefficient for web-services and should
not be activated.
- IP fragmentation
is not supported either (fragmented IP packets are ignored).
Please note that in regular operation conditions any modern OS won't use IP
fragmentation for TCP communication and will instead enable
path MTU
discovery algorithm
therefore you should never have to analyze HTTP traffic inside fragmented
IP packets.
- IPv6 is not supported.
- Neither HTTP/2 nor SPDY are supported.
Other limitations
- The GUI crashes with large capture files, reading more than 100 MB is
not a problem, but several GB will crash the GUI.
I apologize for that, but it won't be fixed until it is easy for me to
provide httppp in 64 bits, i.e. until 64 bits Qt is easy to handle on
MinGW on Windows (until now 64 bits Qt on Windows only work out of the box
for MSVC compiler).
There are no known bugs (provided you read a capture files without any packet
lost, which is nearly impossible), but feel free to report any bug (see
contact address at the bottom of the page).
Download source code or binary packages
Source code is hosted on Gitlab:
Some precompiled binary packages of recent versions are also
available here:
Roadmap and News
There is no official roadmap. However next versions are likely to fix bugs that
may be reported and to circumvent limitations described above.
If you want to be warned when a new version is released, feel free to
follow the project on
Gitlab.
Tech details
Httppp is a Qt/C++
free software
making intensive use of some Qt idioms such as
signals and slots and
implicit sharing.
It uses libpcap to read network capture
files. This is not the most efficient way to process network packet for
analysis, but it was funny to code.
If you want to contribute to the software (or fork it), feel free to use
gitlab links above and clone, do what you want with git, and then
to submit merge/pull requests.
The capture file size limitation is mainly due to httppp GUI being compiled as
a 32 bits executable.
Everything in the source code should be portable to other OSes, especially
MacOS X which is well supported with Qt. I didn't compile it yet by myself
on MacOS X because it would imply finding, downloading, installing and testing
libpcap and a network sniffer.
|

